RAG Overview¶
Understanding how Retrieval-Augmented Generation (RAG) works on the fifthelement.ai platform.
Overview¶
Retrieval-Augmented Generation (RAG) combines the power of large language models with your organization's knowledge base. Instead of relying solely on the LLM's training data, RAG retrieves relevant documents from your knowledge repositories and provides them as context — enabling the agent to give accurate, fact-based responses grounded in your specific data.
How RAG Works¶
The RAG pipeline on fifthelement.ai follows this flow:
- Ingest — Documents are uploaded or crawled into a Knowledge Repository
- Process — Documents are parsed, chunked, and converted into vector embeddings
- Store — Embeddings are stored in a Vector Store (Cognitive Search)
- Retrieve — When a user asks a question, the Retrieval Tool searches the vector store for the most relevant chunks
- Generate — The LLM receives the retrieved context along with the user's question and generates a grounded response
Knowledge Repositories¶
Knowledge Repositories are the containers that store and organize your documents for RAG. Each repository is backed by a Vector Store and optionally a Batch Model for processing.
Creating a Knowledge Repository¶
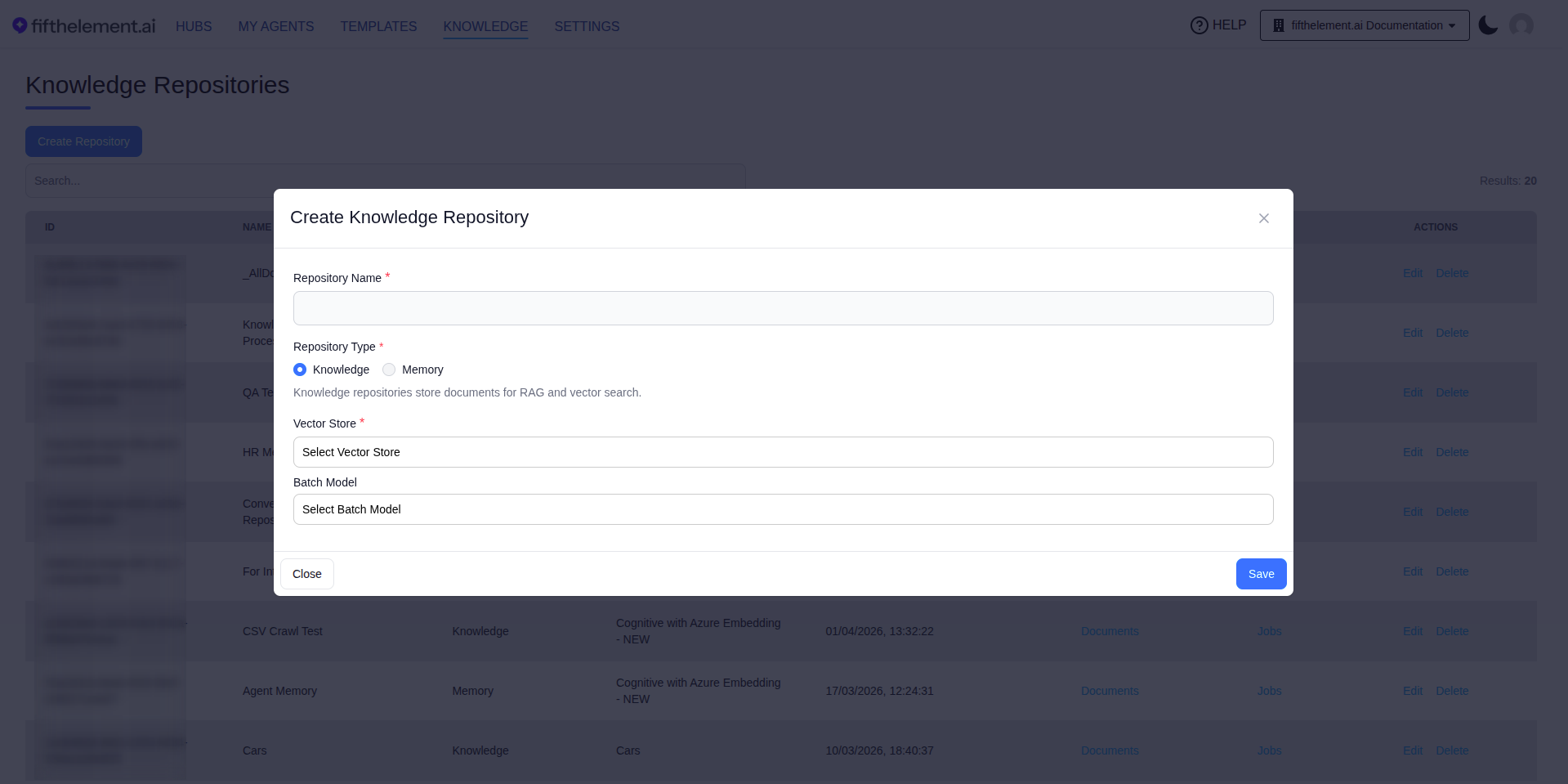
- Navigate to Knowledge from the top navigation
- Click "Create Knowledge Repository"
- Configure the repository settings:
| Field | Required | Description |
|---|---|---|
| Repository Name | Yes | A descriptive name for the repository |
| Repository Type | Yes | Knowledge (stores documents for RAG and vector search) or Memory (used by the Context Memory Tool for persistent agent memory) |
| Vector Store | Yes | Select a configured Vector Store |
| Batch Model | No | Select a Batch Model for document processing (summaries, metadata extraction) |
- Click "Save"
Adding Documents¶
Once a repository is created, add documents using the Add Document(s) button. The platform supports three categories of ingestion:
| Category | Methods |
|---|---|
| Crawl | Website, CSV URL Import, Confluence, SharePoint/OneDrive, Human Assisted |
| Upload | Folder (Auto OCR), Folder (No OCR), Folder (Force OCR), Plain Text |
| API | Add documents programmatically via API |
For detailed instructions, see Document Ingestion and Web Crawling.
Document Management¶
Document Status¶
When batch processing is enabled for a repository, documents move through processing stages:
| Status | Description |
|---|---|
| Processing | Document is being parsed, embedded, and indexed |
| Ready | Document is indexed and available for retrieval |
| Failed | Processing encountered an error |
Document Locks¶
Documents can be locked with keywords to restrict access during retrieval. Only users whose roles have matching document keys can access results from locked documents. This enables role-based document-level security.
Managing Documents¶
From the repository documents page you can:
- Search documents by name
- Filter by Document Status and Document Locks
- Edit document metadata and locks
- View document content
- Delete documents
- Update Locks All — bulk update locks across documents
Connecting RAG to Agents¶
To enable RAG for an agent, you need to connect the knowledge repository through the agent's tools:
- Navigate to Agent Settings > Tools
- Add a Retrieval tool — this performs vector search against the repository
- Alternatively, add a Context tool with Knowledge Repository selected as the context source
The Retrieval tool searches the vector store for relevant document chunks based on the user's query and provides them to the LLM as context for generating responses.
Related Topics¶
- Document Ingestion — Upload files and manage documents
- Web Crawling — Crawl websites and external platforms
- Vector Search — How vector search and retrieval works
- Vector Stores — Configure vector databases
- Embeddings — Configure embedding models
- Tools — Retrieval and Context tools
- Back to Knowledge